
Introduction to Apache Kafka training:
Apache Kafka was first established by LinkedIn, and it is consequently open source in early 2011.Apache Kafka training is a high-performance messaging system. It is a vulnerable basis tool, besides Apache Kafka training is a part of Apache projects. Apache Kafka training offers dispersed and separated messaging system that is extremely error accepting and it can process the lots of mails per instant and send messages to several receivers. Apache Storm is the actual phase stream processing scheme. Apache Kafka training is a vulnerable basis tool and also offers firm and consistent processing of big data and it can process infinite streams that direct statistics to storm constantly.
Idestrainings will provide best Apache Kafka online training by our experts and also provide documents for Apache Kafka training which are prepared by our top professionals.
Prerequisites to Apache Kafka Online Course:
The prerequisites for the Apache Kafka course are:
- Knowledge of any messaging system
- Basic knowledge of Java or any programming language
- Some knowledge of Linux- or Unix-based systems
Apache Kafka online Training Course Details:
- Course Name: Apache Kafka Training
- Mode of Training: We provide Online Training and Corporate Training for Apache Spark Online Course
- Duration of Course: 30 Hrs
- Do We Provide Materials? Yes, If you register with IdesTrainings, the Apache Kafka Training Materials will be provided.
- Course Fee: After register with IdesTrainings, our coordinator will contact you.
- Trainer Experience: 15 years+
- Timings: According to one’s feasibility
- Batch Type: Regular, weekends and fast track
- Sessions will be conducted through WEBEX, GoToMeeting OR SKYPE.
- Basic Requirements: Good Internet Speed, Headset
Apache Kafka Online Training Course Content:
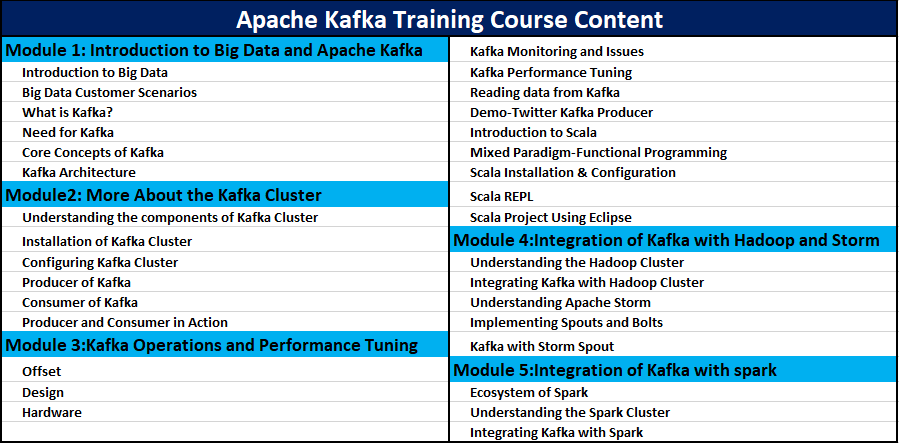
Overview of Apache Kafka training:
- Apache Kafka training is a dispersed streaming stage. In a distinctive messaging scheme there are three modules producer or publisher, broker, consumer producers are the customer submissions besides they direct some ails the broker receive messages from the publisher and store the messages and consumer will read the messages from brokers.
- Stream is a continuous flow of data. Apache Kafka training is so powerful regarding throughput and scalability that it allows us to handle continuous stream of messages if we just plugin some stream processing framework to Kafka it could be backbone and file structure to create a real time stream processing application stream processing read continuous stream of data from Kafka, process them and store them in Kafka.
- Kafka connectors are very powerful features they are ready to use connectors to import data from databases in to Kafka or export data from Kafka to database these are not just out of the box connectors but also the framework to build specialized connectors for any other applications. Our trainers will provide in-depth knowledge on Apache Kafka training.
- Apache storm can interface with messaging queues such as Kafka to get input communication statistics and store the expected statistics in to an actual time big data database such as Cassandra.
What is Apache Kafka?
Apache Kafka is an open source, distributed, notifying framework that monitors and maintains continuous communication from various applications, sites, and so on. Apache Kafka can handle trillions of cases over multiple days. Kafka was originally created for an information line. The Message Lining Framework helps to move information between applications, as opposed to how applications move and share information. This will increase correspondence among manufacturers and buyers who use message-based points. This builds a step above the applications assigned to the New Age. Kafka enables countless permanent or specially designated customers.
Who should take this Apache Kafka online Course?
- Anyone can learn it as this course starts from scratch
- This course is developed for all the Developers and Administrators who want to learn about Kafka servers.
- The people who want to learn more about client – server communication
- Students who wants to do a job in middleware
- Testing Professionals, who are currently involved in Queuing and Messaging Systems
- Big Data Architects, who like to include Kafka in their ecosystem
- Project Managers, who are working on projects related to Messaging Systems
- Admins, who want to gain acceleration in their careers as a “Apache Kafka Administrator”
Why Apache Kafka?
Kafka is very fast because it displays the log data structure as a first class citizen. This is not a traditional message broker with many bells and whistles.
- Kafka does not have personal message IDs. Messages are resolved by their offset in the log.
- Kafka also does not track users who have an item or who uses what messages. All of them are left to the consumer.
- This simplifies the load without handling the indicators that indicate which messages it contains. No random access are the users specify offsets and provide Kafka messages in order, starting with the offset.
- There are no deletes. Kafka keeps all parts of the log for the specified time.
- It can efficiently stream the messages to consumers using kernel-level IO and not buffering the messages in user space.
Apache Kafka with spark streaming:
- Apache Spark is the open source framework for real-time handling developed by the Apache software foundation. Apache Kafka with spark data attains in a stable stream from numerous bases concurrently. Streams on data linked to business connections and can be handled in real time to classify and decline possibly deceitful transactions.
- Apache Spark is considered to be the next generation MapReduce. Apache spark training is a vulnerable basis scheme apache spark training is used to transform dispersed statistics that provides the data transforms beyond map and reduce it processes data quicker than Hadoop MapReduce when entire data fits in memory spark is found to be 100 times closer than Hadoop MapReduce whereas in other cases it is found to be at least 10 times closer.
- Spark is appropriate for a group in real time processing it provides sparks SQL for a SQL interface to big data and also provides built-in libraries for machine learning and graph processing.
- Mechanism erudition contains of packages that can learn built on the statistics without being clearly programmed a graph is a set of nodes and ends linking these nodes graph processing contains of procedure to process the nodes and edges of graph.
Nodes of cluster in Apache Cassandra using Kafka:
Kafka is the tube over which you stay sending messages and Cassandra can store the things which are stored at the starting is the store where things are finally stored.
- Cassandra is nothing but a free open source no sequel database but stores the value in the form of key-value pairs so that Cassandra stores the data in the form of key-value pairs. Cassandra is highly robust because it has a master less replication. Cassandra basically works inthe principle of clustering.
- Cassandra is extremely and horizontally accessible with thousands of nodes in a cluster. It greatly offers mechanisms which are also called nodes are sensibly prearranged in the ring architecture. Cassandra also offers a simple SQL interface and an interface is similar to SQL to insert update and select the data it is a key value database each row of a data has a primary key to identify the data.
Apache Hbase in Apache Kafka training:
- Apache HBase is an another vulnerable basis and it ensures not has SQL file it is dispersed file with columnar storing that is built on top of HDFs it offers real time read and write accidental entrance to statistics and also maintenance’s big files in the order of terabytes and Peta bytes.
- HBase training is not interactive besides it does not support SQL actual period. big data refer to management a huge quantity of commercial statistics as soon as statistics is generated to get valued visions and recommend instant actions here time refers to event that occurs using actual period big data tools we can read and write data in real time and also filter and collective in actual time visualize data in real time process millions of records per second.
- We also provide Apache Hbase at Idestraining’s by industry experts. Along with Apache Kafka training Apache HBase training will also be provided in detailed manner by our well experienced trainers.
What’s the role of Zookeeper in Kafka?
Every Kafka broker manages through additional Kafka brokers using Zookeeper. Producers and Consumers are advised by the Zookeeper facility nearby the existence of new brokers or failure of the broker in the Kafka system.
What is the use of Fault tolerance in Kafka?
- Fault tolerance is the property that enables the system to continue operating properly in the event of the failure of one or more faults with in some of its components. If its operating quality decreases it decreases the proportionality to severity of the failure as compared to the designed system in which even a small failure cause total breakdown.
- Apache Kafka training is a distributed system and it works on the cluster of computers. Most of the time Apache Kafka training will blowout our data in panels above many schemes in the group if single or dual schemes flops in the group we cannot read the statistics that’s a mistake. The term fault tolerance is very common in distributed systems it means making data available even in some case of failures.
- Solution is to make many duplicates of data and save it on discrete systems so if we require 3 copies of a partition Kafka supplies them on 3 different machines so that we can be able to avoid 2 failures since we have 3 copies on 3 different systems even if two of them fails we can read the data from the third system.
- There is a particular term used for making multiple copies we call that as replication factor so if the replication factor is three means we are maintaining 3 copies of my partition. Kafka outfits mistake acceptance through relating repetition to the partitions we can describe repetition issue clear for theme level. Here we don’t set the replication factor of partitions is set it for a topic and it applies to all partitions with in the topic.
- Apache Kafka training outfits a leader and follower model thus for each panel broker is selected as a leader besides the leader takes care of entire customer connections this means while a producer sends some data it connects to leader and starts sending data it is a leaders responsibility to receive the message and store it in local disk and send back an acknowledgement to producer.
- similarly, when a consumer is willing to read data it sends a request to the leader it is leaders responsibility to send a requested data back to the consumer for every partition we have a leader and the leader takes care of all the requests and responsive. Our trainers will provide Best apache Kafka online training with real time examples. For more details about this module please register with our website.
Conclusion of Apache Kafka training:
Apache Kafka has converted the de-facto standard for actual data analytics and LinkedIn is not the only company that is attaching huge streams of data. With Kafka, one can be guaranteed to excel in their Big Data Analytics career. Apache Kafka use dispersed streaming policy it is one of the most authoritative and commonly used consistent streaming platforms. Kafka is a fault tolerant. Apache Kafka training uses the enterprises like Apple Inc., Bet fair, Cisco systems and others. The average salary for Kafka professional is 1, 22,000$ per annum. This is higher than the average salaries of other jobs.
Apache Kafka training will provide overview to Kafka and its structural design, Use case for Kafka, Partitions, and Kafka functioning on command line, producers and consumers, consumer groups, Kafka messaging order, Generating producers and consumers with Java API. Enroll for Apache Kafka training at Idestrainings. We have best trainers to guide you and the classes will be provided during the weekends or weekdays based on the students demand. We also offer many other courses based on industry needs.